インテルによる「ポーカーの手の判別の並列化」
インテル デベロッパー・ゾーンで公開されている「C++ 11 でマルチスレッド・コードを記述する」という記事の,「ポーカーの手の判別は並列化しても速くならない」という主張について調べた結果,私の環境で4.9秒かかる元記事の処理が,0.68秒で終わるようになりました.(コード)
計測すべし。計測するまでは速度のための調整をしてはならない。(ロブ・パイク)
オリジナルのpokereval/pokereval.cppを見ながら作業しましょう.
Step 1:実験の意義
タスクの中でスリープするのはやめましょう.そういうことをすればマルチスレッド版がシングルスレッド版より速くなるのは当然ですが,意味がありません.105行目を書き換えます.
//Sleep(1);
Step 2:データセット
2万件(正確には19981件)ではすぐに終わってしまうので,100万件のデータを使いましょう.207行目を書き換えます.
std::ifstream filein("hands1million.txt");
Step 3:シングルスレッド版の実行時間
シングルスレッド版はこれで動くので,この実行時間を基準にチューニングします.
筆者のPC(i7-4930K,Visual Studio Community 2017,Win32 Releaseモード)では,4.9秒でした(シングルスレッド版・オリジナル).
Step 4:バグ修正
マルチスレッドのコードにバグが2個あるので修正します.(補足:この修正はpull requestしました.)
(1) 入力の終わりの判定が間違っていて,hands1million.txtの最後の空行をカウントしています.283, 284行目の,
if (filein.eof()) break;
std::getline(filein, str);
を次で置き換えます.
if (!std::getline(filein, str)) break;
(2) スレッド数の倍数だけ処理したところで出力していますが,最後に余った分を出力し忘れています.299行目の#elseの前に,次を挿入しましょう.
if (count != MaxThreads - 1) {
for (int i = 0; i < count; ++i) {
fileout << futures[i].get() << '\n';
}
}
Step 5:マルチスレッド版の実行時間
269行目の#define Multi 1を有効にして,マルチスレッド版の実行時間を計ります.
筆者のPCでは5.7秒でした(マルチスレッド版・オリジナル).
マルチスレッド版がシングルスレッド版(4.9秒)より遅いと悔しいのは確かです.
Step 6:計測
Visual Studioの,デバッグ→パフォーマンス プロファイラーで,関数ごとのCPU使用率を計測します.
測定結果の上位は次のようなものでした.
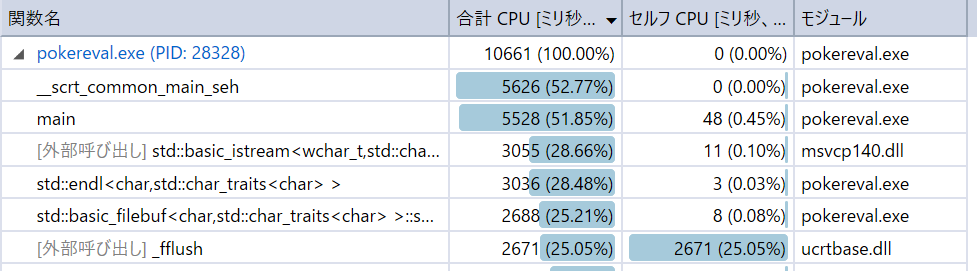
std::basic_istreamに一番時間がかかっています.もう少しよく見ると,その大部分は,std::endlで費やされているようです.
Step 7:パフォーマンスチューニング

『C++の教科書』の8.2.3項に,endlはバッファをフラッシュさせると書いてあります.100万件のデータの出力する際に,1件ごとにフラッシュするのはまずいでしょう.294行目のstd::endlを'\n'に置き換えます.
fileout << e.get() << '\n';
筆者のPCでは2.5秒でした(マルチスレッド版・修正後).
残念ながら,これでシングルスレッド版(4.9秒)を上回ったわけではありません.シングルスレッド版のコードでもstd::endlを'\n'に置き換えて(256行目),実行時間を計ります.
筆者のPCでは1.4秒でした(シングルスレッド版・修正後).
依然として,マルチスレッド版よりシングルスレッド版の方が高速です.
とはいえ,元記事の「評価の実行時間が短すぎて、タスクを非同期に呼び出すオーバーヘッドが原因である」という考察は疑問です.ここで解いているのはいわゆる embarrassingly parallel というやつで,並列化の効果が,「あって当然」だからです.
Step 8:OpenMP
OpenMPを使いましょう.『C++の教科書』の12.4節に使い方が載っています.
マクロで場合分けしてもかまいませんが,シングルスレッド版のコード(300から306行目)を書き換えます.データをメモリに読み込んで,OpenMPで並列に判別し,結果を出力します.
std::vector<std::string> hands;
while (std::getline(filein, str)) {
hands.push_back(str);
}
rowCount = hands.size();
std::vector<std::string> results(rowCount);
#pragma omp parallel for
for (int i = 0; i < rowCount; ++i) {
PokerHand pokerhand(hands[i]);
auto result = EvaluateHand(pokerhand);
results[i] = pokerhand.GetResult(result);
}
for (int i = 0; i < rowCount; ++i) {
fileout << results[i] << '\n';
}
筆者のPCでは0.68秒でした(OpenMP版).これでシングルスレッド版・修正版(1.4秒)より速くなりました.シングルスレッド版・オリジナル(4.9秒)よりはかなり速いです.ちなみに,OpenMPを有効にしない状態でのこのコードの実行時間は1.7秒でした.
まとめ:ポーカーの手の判別は並列化で速くなります.